Structured Coding Techniques and Perfect Coding Styles
The use of structured coding techniques and styles supports the primary goal of implementation to write quality source code and internal documentation that aid in easy verification with specification, debugging testing and modification. The source code thus generated will be simple, clear and elegant and less obscure, clever and complex.
Structured coding techniques aids in linearizing the control flow through a computer program so that the execution sequence follows the sequence in which the code is written. This dynamic structure of a program as it executes them resembles the static structure of the written text which improves code-readability, debugging, testing, documentation and modification of programs. The following are some of the golden rules to be considered for structured coding.
- Single entry, Single exit constructs
Single entry, single exit constructs are control structures that enables us to create sequencing, selection and iteration constructs. The term single entry, single exit is used since such constructs have a single entry or single path of inflow of data and a single exit or single path of outflow. The following are the common single entry, single exit constructs –
Sequencing Construct
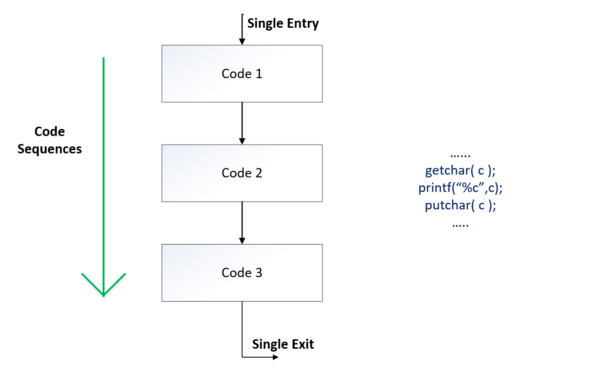
Selection Construct
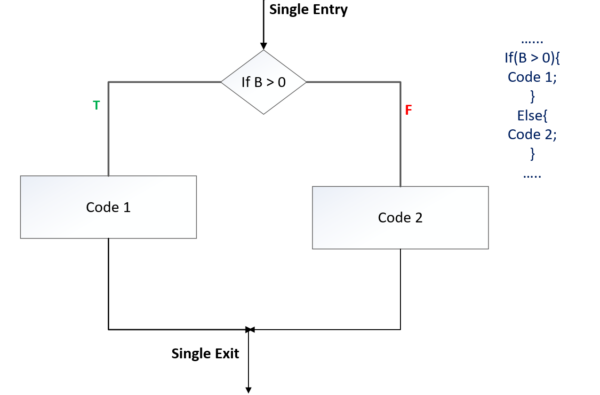
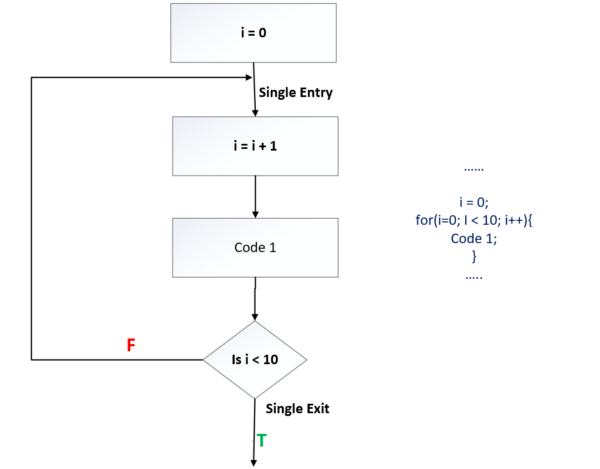
Iteration Construct
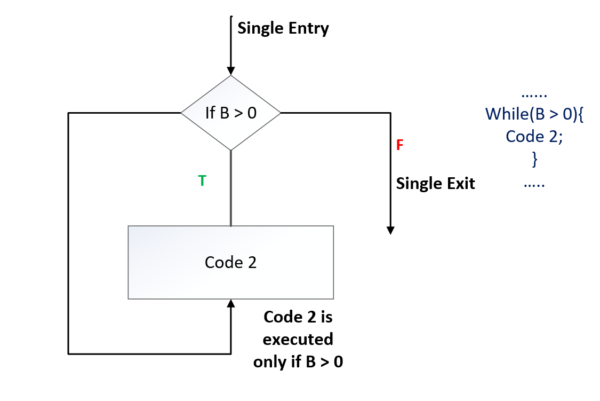
Type 1: while-do looping
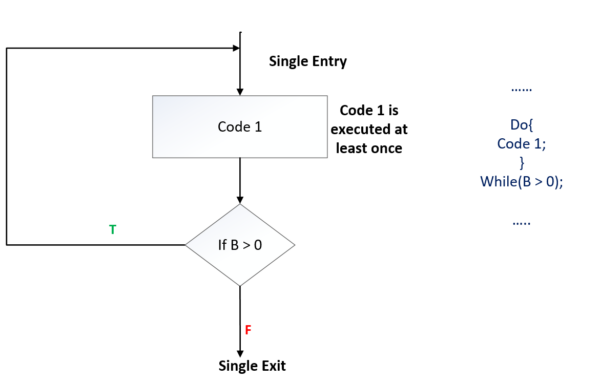
Type 2: do-while looping
Type 3: for loop
In cases when we require multiple loop exits, we may apply ‘go to’ as some languages allow it or should redesign the algorithm to avoid multiple loop exits, which is the desired practice. Alternatively in such cases, we may use the exit or ‘break’ statement as follows –
while (cond 1){
Code 1;
Code 2;
if (Cond 2){
break;
}
}2. Data encapsulation
Data encapsulation is the process of encapsulating the data operations of an object from outside interference or misuse. In object oriented languages such as C++, C# or Java, we implement data encapsulation by class abstractions. In such a case the class itself doesn’t have physical existence and is only a logical abstraction. When a class is instantiated, it creates objects with the encapsulated data and operations. Now, other outside groups or objects could access the internal data structure, but only the specific object. In this way, we encapsulate data and code within each object. Again, another advantage of encapsulation is that, the data attributes or data structures are made private within a class and only the object’s public functions may access and manipulate them. Encapsulation supports abstract classes (those which cannot be instantiated but whose abstract functions may be redefined or implemented) and polymorphism (single implementation, multiple signatures).
In C++, we may encapsulate data and code within a class declaration as follows –
class Stack {
private:
int stk[MAX];
int stktop;
public:
void init();
void push(int i);
void pop();
} stack 1;Class Stack is an abstraction of data and operations as show above and stack 1 is the object that instantiates the class and which has access to the encapsulated data and code.
3. Recursion
A recursive programming style may be applied when the iterative processing may be indirectly performed by recursively calling the same program. Recursive algorithms may be applied, for eg:., in traversing a binary tree as follows –
/*Recursive C routine for inorder traversal*/
void intrav(NODEPTR){
if(tree != NULL){
intrav(tree->left);/*traverse left subtree*/
printf("%d",tree->info);/*visit root*/
intrav(tree->right);/*traverse rightsubtree*/
}
}Recursion is supported by a system provided stack to hold values of local variables, parameters and return points. Recursion cannot be performed on a routine under static memory management as in case of old Fortran or similar languages since it leads to overwriting of the original return address for the routine/method.
Recursion is not appropriate for implementing algorithms that are inherently iterative and could be implemented clearly by iteration. For eg: factorial calculation and Fibonacci operation. The reason is that there is no need for recursion as its really needed in case of binary tree traversal or backtracking algorithms used in AI.
3. Coding Style
The following are some of the major guidelines that dictates a perfect codig style
-DO –
3.1. Use a few standard control constructs – i.e, use limited number of standard control constructs such as those enabling sequencing, selection and iterations.
3.2. Use Gotos in a disciplined manner – Gotos may be applied in coding when multiple loop exits or control transfer to exception handling routines is un-avoidable. In all these cases, use of Goto statements should be in a stylish, disciplined manner to achieve the desired result. The acceptable use of Goto statements are almost always forward transfers of control within a local region of code and with traditional functional languages. Most of the modern programming languages provides various constructs such as exit, break, continue exception statements to transfer the control of execution without using goto.
3.3. Introduce user-defined datatypes to model entities in the problem domain – For eg:, C allows users to define data types of their own using the ‘typedef’ keyword as follows –
typedef struct{
int numerator;
int denominator;
}RATIONAL;The above type declaration creates a user defined struct type RATIONAL. Now, we may create a new structure ‘r’ by defining RATIONAL r;
C also allows the definition of user defined enumerated types which gives a list of values for a user defined data type as follows –
typedef enum day = { SUN, MON, TUE, WED, THU, FRI, SAT };
day day1;The above statement creates a user defined enumerated datatype ‘day’ which has the possible values SUN, MON, TUE, WED, THU, FRI, SAT where S has position value = 0, MON = 1 and so. on ..
3.4. Hide data structures behind access functions. Isolate machine dependencies in a few routines – We may use information hiding to hide the data structures that should not be visible to outside objects and functions. By doing so, each module makes visible only those features required by other modules. Such information hiding is supported by data encapsulation mechanisms such as class declaration in object oriented programming languages.
The purpose of isolating the machine dependencies in a few routines is to ease program portability.
3.5. Provide standard documentation prologues for each subprogram and/or compilation unit – A documentation prologue contains information about a sub-program or compilation unit that is not obvious from reading the source code. The exact form and content of a prologue depends on the nature of implementation language.
3.6. Use indentation, parenthesis, blank spaces, blank lines and borders around blocks of comments to enhance code readability
– DONT –
3.7. Do not use programming tricks – Don’t use programming tricks to too clever codes which may be inefficient and unstructured, un-readable and unmaintainable.
3.8. Avoid null-then statement – Null – Then statement is of the form
if B; { ;}
else { Code 1; }Above code may be replaced as –
if (!B) { Code 1;}
3.9. Avoid then – if statements – A then – if statement is as follows which may create obscure operations if not handled efficiently –
....
if (A > B){ /* then - if situation start */
if (C < D){ /* then - if situation end i.e 2 if close to each other as in this case*/
Code 1;
}
else{
Code 2;
}
}
else{
Code 3;
} ......The above then-if situation may be simplified as follows –
....
if (A < B){
Code 3;
}
else if (C < D){
Code 1;
}
else{
Code 2;
} ......3.10. Avoid routines/methods that causes obscure side effects
3.11. Don’t sub-optimize – Sub-optimization occurs when one devotes inordinate effort to refining a situation that has little effect on the overall outcome.
3.12. Carefully examine methods/routines having than 5 formal parameters – Methods/function with longer list of parameter values results in complex routines that are difficult to understand and difficult to use and they result from inadequate decomposition of a software system. Fewer parameters and fewer global variables improve the clarity and simplicity of code. In this regard, 5 is a very descent upper bound.
3.13. Don’t use an identifier for multiple purposes – Programmers most frequently use a single identifier for multiple purposes for saving memory since as number of variables/identifiers is increased, the number of memory calls to be allocated is also increased. Such a practice is not recommended due to 3 reasons –
- each identifier define a specific purpose and not various purposes
- use of a single identifier for multiple purposes indicates multiple regions of code which leads to low cohesion
- it makes the source code very sensitive to future modifications
3.14. Don’t nest the loops too deeply – Deeply nesting loops will make it difficult to determine the conditions under which statement in the lowest loop will be executed and such a practice is a poor design. Nested loops exceeding 3-4 levels should be avoided.
4. Documentation
Structured programming constructs, good coding style, meaningful identifier names to denote user-defined data types, variable, enumerators, literals, parameters can vastly improve code readability and reduce the need for internal documentation. Some of the general guidelines for internal documentation is as follows –
- Minimize the need for embedded comments by using
- Standard prologues
- Structured programming constructs
- Good Coding style
- Descriptive names from the problem domain for user-defined data types, variables, formal parameters, enumeration literals, methods, files etc.
- Self documenting features of the implementation language such as user-defined exceptions, user defined data types, data encapsulation etc.
- Attach comments to blocks of code that
- perform major data manipulations
- simulate structured control constructs
- perform exception handling
- Use problem domain terminology in the comments
- Use blank lines, borders, and indentation to highlight comments
- Place comments to the far right to document changes and revisions
- Don’t use long, involved comments to document obscure, complex code, instead rewrite the code
- Be sure that the comments and code agree with one another and with the requirements and design specifications.